SQL Server2014 哈希索引原理详解,server2014
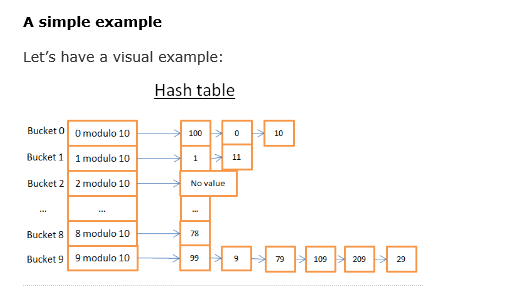
当一个key-value键值对传递给一个哈希函数的时候,经过哈希函数的计算之后,根据结果会把key-value键值对放在合适的hash buckets(哈希存储桶)里
举个栗子
我们假设对10取模( % 10 )就是哈希函数。如果key-value键值对的key是1525 ,传递到哈希函数,那么1525 会存放在第五个bucket里
因为5 as 1525 % 10 = 5。
同样,537 会存放在第七个bucket ,2982 会存放在第二个bucket ,依次类推
同样,在hash index里面,哈希索引列会被传递给哈希函数做匹配(类似于java里面的HashMap的Map操作),匹配成功之后,
索引列会被存储在匹配到的hash bucket里面的表里,这个表里会有实际的数据行指针,再根据实际的数据行指针查找对应的数据行。
概括来说,要查找一行数据或者处理一个where子句,SQL Server引擎需要做下面几件事
1、根据where条件里面的参数生成合适的哈希函数
2、索引列进行匹配,匹配到对应hash bucket,找到对应hash bucket意味着也找到了对应的数据行指针(row pointer)
3、读取数据
哈希索引比起B树索引简单,因为它不需要遍历B树,所以访问速度会更快
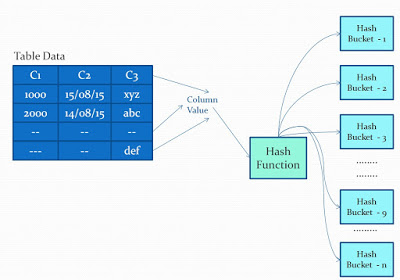
哈希函数和相应语法的例子
CREATE TABLE dbo.HK_tbl ( [ID] INT IDENTITY(1, 1) NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH ( BUCKET_COUNT = 100000 ) , [Data] char(32) COLLATE Latin1_General_100_BIN2 NULL , [dt] datetime NOT NULL, ) WITH ( MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA);在SQL Server 2014里面,内存优化表创建完之后就不能再加哈希索引了,但是在 SQL Server 2016 里支持表创建完之后添加哈希索引,不过
添加哈希索引是一个离线操作。
哈希索引的Bucket 数量
( BUCKET_COUNT = 100000 )定义了哈希索引能够使用的BUCKET数量,这个Bucket 是固定的并且由用户指定Bucket 数量,
而不是执行查询的时候由SQL Server决定生成的Bucket 数量。BUCKET数量总是2的次方的四舍五入( 1024, 2048, 4096 etc..)
SQL Server2014的哈希索引其实跟MySQL的自适应哈希索引原理其实差不多,都是为了摆脱B树的束缚,使查找效率更快
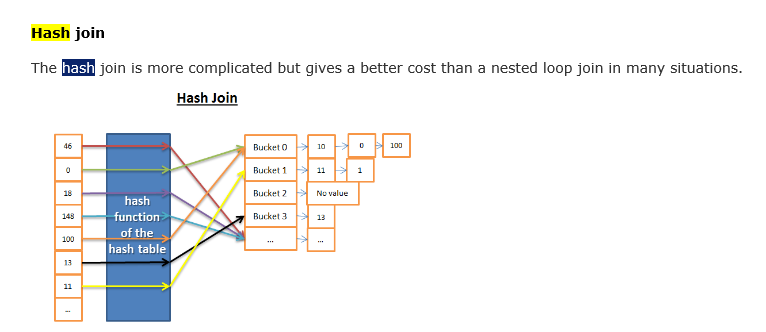
How does a relational database work这篇文章也有描述hash join的原理,大家可以看一下