详释mysql全文索引性能测试分析
mysql全文索引性能测试如下:
测试机:SVR644HP380
内存容量:8G
MySQL 版本:5.6.12
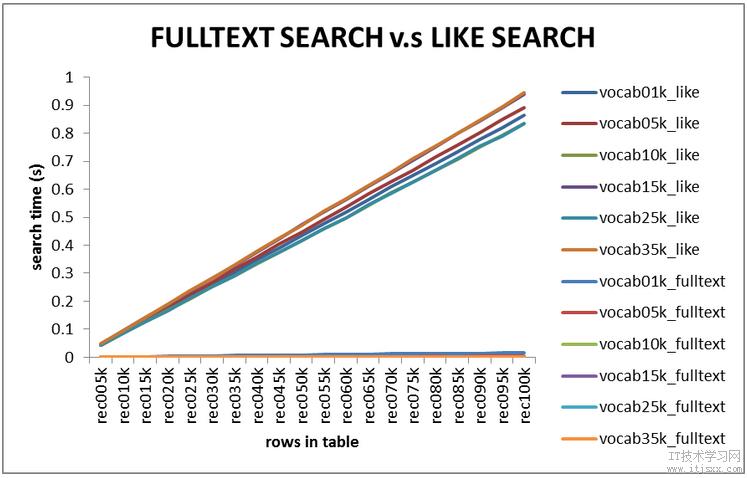
测试结果:FULLTEXT检索与LIKE检索对比,0.1秒以上的全部为like检索。
测试设计
词汇量:6个等级,分别用vocab01k、vocab05k、vocab10k、vocab15k,vocab25k、vocab35k标记,每个等级的词汇数如下,1000、5000、10000、15000、25000、35000。(取牛津词典单词部分,去重复后随机打乱顺序,分别截取前1000、5000、10000……作为对应的词汇量)
记录数:20个等级,分别用rec005k、rec010k、rec015k、rec020k、……rec095k、rec100k标记,每个等级的记录数如下,5000、10000、15000、20000、25000、30000、……、95000、100000。
根据词汇量等级和记录数等级分别生成含不同记录数且表中文本列是由对应的词汇量生成的随机文本的表,共6*20=120个。表的存储引擎使用InnoDB。表由id和body两个字段组成,分别为整型和文本型,且在body列创建了FULLTEXT索引。表名的命名规则为vocab01k_rec005k,表示该表中共含有5千条记录,每条记录中的body列由vocab01k对应的词汇量生成的随机单词组成,以此类推。每行记录中的body列定为由50个随机单词组成。
比较两类查询:LIKE从句查询以及使用FULLTEXT索引的MATCH()AGAINST()查询。在每个表上分别执行LIKE查询和MATCH() AGAINST()全文查询,每个表上的每个查询分别执行50次,记录每次所耗费的时间。对于每50个消耗的时间,删除其最大两个值和最小两个值,取剩余值的均值作为查询耗时的最终结果。这样一共可获得120*2 = 240个时间数据,根据这些数据绘图。在每个表上执行的查询如下(其中random_word1、random_word2、random_word3是根据查询时表对应的词汇量生成的随机单词。):
LIKE搜索:
SELECT body FROM table_name WHERE body LIKE "%random_word1%" AND bodyLIKE "% random_word2%" AND body LIKE "% random_word3%";
FULLTEXT搜索:
SELECT body FROM table_name WHERE MATCH(body) AGAINST("+random_word3 + random_word3+ random_word3" IN BOOLEAN MODE)
结果讨论
LIKE搜索的耗时随着记录数的增加而线性增长,但对于10万行记录以下的表(这里共100000*50个单词)搜索时间基本上能保持在1秒以内,所以like搜索的性能也不是特别差。由不同词汇量生成的文本对LIKE搜索的性能影响不大,不同词汇量对应的搜索时间基本上在一个很小的时间范围内变化。
FULLTEXT搜索耗时也随表中记录数的增长而线性增加。对于10万行记录以下的表(这里共100000*50个单词)搜索时间基本上能保持在0.01秒以内。由不同词汇量生成的随机文本对FULLTEXT搜索性能有相对来说比较显著的影响。每行记录中含同样的单词数,这样,较大的词汇量倾向于生成冗余度更低的文本,相应的搜索耗时倾向于更少。这可能与FULLTEXT索引建立单词索引的机制有关,较大的词汇量倾向于生成范围广但相对较浅的索引,因而能快速确定文本是否匹配。
与LIKE搜索相比,FULLTEXT全文搜索的性能要强很多,对于10万行记录的表,搜索时间都在0.02秒以下。因此可以将基于FULLTEXT索引的文本搜索部署于网站项目中的文本搜索功能中。