mysql校对规则(COLLATION)详细解释
mysql校对规则(COLLATION)详解
一、前言
有时候遇到这种情况,你用一个like语句查询,查到的结果中有一些并没有包含你查询的关键词的纪录;
有时候遇到这种情况,你的数据库自作聪明的大小写不敏感,让你在更新时把大小写不同的两条记录都更新了;
有时候遇到这种情况,你的查询语句一切正常,查询却失败了,报告Illegal mix of collations错误;
你很困惑,在想数据库是不是坏了。。。其实 ,这些都和数据库字符集的校对规则有关;了解了校对规则,你就知道怎样处理这些问题。
那么,校对规则是怎么回事呢?它是一组规则,负责决定某一字符集下的字符进行比较和排序的结果。
比如说,有latin1字符集中的字母A和a,我们需要它们在比较的时候相等,那么,我们可以使用字符集校对规则 latin1_general_ci;这种校对规则在比较和排序的时候不区分大小写;如果我们需要他们在比较的时候不等呢?也很简单,我们可以使用字符集校对规则latin1_bin;这种校对规则会以二进制的方式对字符进行比较,很明显,a和A的二进制编码不同,比较的结果就是不等。
上面的场景说明了校对规则在最简单情况下起的作用;实际情况与此并没有太多不同,只不过稍微有些复杂而已。
二、校对规则总览
我们可以使用 SHOW COLLATION 指令来查看数据库支持的校对规则
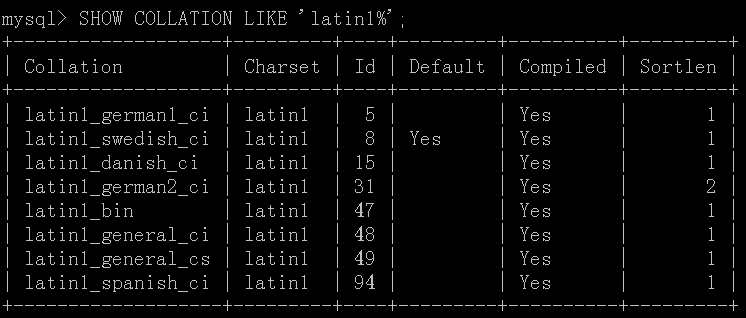
在图中,我们列出了数据库支持的latin1字符集的校对规则。为什么一种字符集竟然有这么多种的校对规则呢?因为在不同的情况下,对比较的结果有不同的期待,所以就有了不同的校对规则。前面说的大小写敏感(latin1_general_cs)和不敏感(latin1_general_ci)是两种校对规则,根据二进制方式进行比较(latin1_bin)也是一种校对规则,德国人(latin1_german1_ci)和西班牙人(latin1_spanish_ci)使用的某些不同的拉丁字符在某些情况下是等价的,所以有了两种新的校对规则。
举个例子,在latin1_german1_ci中,如下字符是等价的,而他们,具有不同的外形和编码。当然,它们的编码不同,所以在latin1_bin校对规则下,他们又是不等价的了。
A,a,À,Á,Â,Ã,Ä,Å,Æ,à,á,â,ã,ä,å,æ
三、校对规则导致的问题
1、混合校对规则比较
两个字符串比较,要求两者必须有相同的校对规则,或者两者的校对规则是相容的——所谓相容是指,两种校对规则优先级不同,比较的时候两者使用高优先级的校对规则进行比较,比如latin1_bin的优先级相对较高。
CREATE TABLE `tbl` ( `col_a` int() default NULL, `col_b` , `col_c` , `col_d` , KEY `col_a` (`col_a`), KEY `col_b` (`col_b`) ) ENGINE=MyISAM DEFAULT CHARSET=latin1
在这个表中,col_b、col_c、col_d的校对规则各不同;其中,latin1_general_ci和latin1_german1_ci 校对规则同级,不能进行比较;如果强行比较的话,就会报错,如下:
mysqltbl where col_b = col_c; ERROR (HY000): Illegal mix
而latin1_general_ci和latin1_bin的优先级不同,latin1_bin高于latin1_general,因此比较的时候,会按照latin1_bin的规则进行比较。
mysqltbl where binary col_b = col_d; Empty set (0.00 sec)
当然,可以在sql语句中强制指定校对规则进行比较,下面这个例子就说明了这一点:
mysqltbl where col_b COLLATE latin1_danish_ci = col_c COLLATE latin1_danish_ci; Empty set (0.00 sec)
2、校对规则导致的问题——SELECT出错误的记录
在上面的基础上,我们要演示一个常见的问题;我们需要对该数据表进行一定的处理:
; );
然后进行下面的查询

我们希望查询的是包含“刘”的记录,hao123这个和“刘”没有任何关系的条目被选了出来,看起来很奇怪。
不过这不是数据库出了问题,而是校对规则的使用上存在问题:
下面是我们使用ultraedit察看字符串的二进制编码的结果,在gbk编码下,hao123的编码为68 61 6f 31 32 33,而刘的编码位C1 F5。
在前面的latin1_swedish_ci 校对规则中可以看到:
61和C1都与41等价
6F和F5都与4F等价
这就是ao = 刘的原因。
解决办法有两个:
1)修改该字段的字符集和校对规则,改成gbk,这该问题不在存在。这是完美的解决方案,不过有些时候你没有权限对数据库进行这样的改动。
mysqltbl modify col_b char() charset gbk default null; Query OK, row affected (0.01 sec) Records: Duplicates: Warnings: mysqltbl ; Empty set (0.00 sec)
2)查询的时候声明校对规则为latin1_bin 。这样可以在一定程度上缓解这个问题;不过如果col_b中只要含有c1 f5,就会被选出来——而c1 f5可能恰好是另外两个字符的前半截和后半截,或者干脆就是 Á õ ....
mysqltbl ; Empty set (0.00 sec)