错新网讯
1 概述
1977年,DEC公司推出了以VAX为结点机的松散耦合的集群系统,并成功地将VMS操作系统移植到该系统上。20世纪90年代以来,随着RISC技术的发展和高性能网络产品的出现,集群系统在性能价格比(Performance/Cost)、可扩展性(Scalability)、可用性(Availability)等方面都显示出了很强的竞争力,尤其是它在对现有单机上的软硬件产品的继承和对商用软硬件最新研究成果的快速运用方面表现出了传统大规模并行处理机(Massively Parallel Processor,MPP)无法比拟的优势。
目前,集群系统已在许多领域获得应用。可以预见,随着对称多处理机(Symmetric Multiprocessor,SMP)产品的大量使用和高性能网络产品的完善,以及各种软硬件支持的增多和系统软件、应用软件的丰富,新一代高性能集群系统必将成为未来高性能计算领域的主流平台之一。具有代表性的集群系统有IBM的SP2、SGI 的POWER CHALLENGEarray、Microsoft的Wolfpack、DEC的TruClusters、SUN的SPARC cluster 1000/2000PDB以及Berkeley NOW等。我国国家智能计算机研究开发中心的曙光-1000A、曙光-2000I和曙光-2000II也都属于集群系统的并行计算机。简单地说,并行计算机就是用若干(几到几千)处理器并行执行一个作业,以提高计算效率。并行计算机的结构、规模、性能可以有很大的差异,其价格也就可以从人民币数万元到数亿元。以较低的投资,用若干台性能较高的PC机组装成集群并行计算机,采用Linux操作系统以及目前在各类并行机上通用的信息传递接口MPI并行环境,以此为起步发展并行计算和研究,是一个合适的选择。计算机科学技术的发展在高性能计算领域为其他科学技术的发展提供了越来越宽广的平台。另一方面,科学技术的发展对高性能计算环境(硬、软件)不断提出更高的要求。以磁约束聚变研究为例,磁约束受控核聚变研究是以探求未来能源为目标的。托卡马克(TOKAMAK)是磁约束受控核聚变研究中进展最快、参数最高的研究途径。20世纪90年代在欧美的托卡马克上成功进行的氘-氚聚变反应实验,使得磁约束受控核聚变的科学可行性得到了初步证实。目前人们正从作为聚变能源的要求来开展托卡马克研究。托卡马克的研究对象是高温等离子体,是一个具有巨大数目(例如1020个)自由度的极为复杂的非线性系统。数值模拟是主要的研究手段之一。在我国,随着核聚变等离子体物理研究(托卡马克实验、理论和数值模拟)不断取得新的进展,特别是国家大科学工程HT-7U超导托卡马克计划的实施,对高性能计算提出了更高的要求。针对特定的研究领域,在一定的财力资源下,集群并行计算机可以为数值模拟的发展提供串行计算机系统所无法比拟的高效平台。
2 Beowulf集群系统简介
Linux环境下的集群系统中比较有影响的是Beowulf集群。Beowulf集群的研究是由美国国家航空航天局(NASA)于1994年启动的。1994年,Thomas Sterling和Don Becker等人构建了一台由以太网连接的拥有16个DX4处理器的集群。他们把这个集群计算机叫作Beowulf,主要用来进行地球、空间科学的研究。Beowulf的主要目的是使用普通的、相对廉价的计算机构建能够处理繁重计算的集群。此后,Beowulf的思想迅速被世界上许多研究机构认同和接受。在Beowulf集群上运行的软件是Linux操作系统、并行虚处理机(Parallel Virtual Machine,PVM)和消息传递接口MPI(Message Passing Interface)。一般由服务节点来控制整个集群。服务节点是集群的控制台和对外的网关。在规模比较大的Beowulf集群中可以有多个服务节点,例如专门用集群中的一个节点作为控制台或统计整个集群的运行状态。通常,除服务节点外,Beowulf集群中的其他节点都是哑成员,即它们不与外界交互。这些成员节点由服务节点来管理,执行服务节点分配的任务。
Beowulf集群中的成员节点以及内部连接是集群专用的。从这一点来看,Beowulf更像是一台完整的机器,而不是一个由许多计算机组成的松散的群体。集群下的大多数节点没有键盘、显示器等,只是通过远程登录来访问控制它们。就像CPU和内存可以方便地安装到主板上一样,Beowulf的节点作为内置的模块插入Beowulf集群中。Beowulf集群中的节点之间的连接(通常是高速网络,比如FastEthernet、ATM、Myrinet等)也是仅供节点间使用,它与集群与外界连接的普通网络相隔离。这些特点使得Beowulf集群中各节点的负载均衡且节点之间的信赖关系变得更容易处理,因为它们不受外界的影响。同时,节点之间的通信也会更高效。Beowulf并不是一个软件包、一种新的网络拓扑结构或者内核技术,而是一种基于Linux操作系统的机器来构建并行虚拟机的思想。尽管有很多软件(例如:内核的修改,PVM和MPI并行运算库或者管理工具)可以使Beowulf体系结构更快、更容易管理和使用,但仍然可以只使用Linux来建造一个自身的Beowulf集群。一个最简单的Beowulf集群可以由两台互相连接并且拥有一些信任关系(比如NFS和rsh权限)的Linux计算机组成。
3 Beowulf集群系统硬件配置和结构
我们采用9台CPU为PIV-1.5GHz、内存为512M、硬盘为40GB/7200RPM、配有双网卡的普通PC机作为节点组成集群机,实现基于消息传递的分布式内存的并行计算机系统。采用CISCO2900XL系列交换机(24口/100M),将交换机设置为3个虚拟网段,其中的一个网段设置为信息接收网段(LAN1),另一个网段设置为信息发送网段(LAN2)。LAN1只负责接收来自节点计算机的消息,将接收到的消息发送到LAN2的各个端口,LAN2将消息发送到相应的节点计算机,以使各节点计算机的两个网卡分别进行消息的发送和接收,提高消息传递的速度。交换机的第3个网段用于将系统与局域网连接,从而实现远程登陆服务等功能。
4 Beowulf集群系统Linux操作系统以及并行编程
环境的安装
在本系统中,我们采用的操作系统是RedHat 7.1 (内核2.4.2-2smp)的Linux系统。并行编程环境采用基于消息传递接口(MPI) 的局域多计算机(Local Area Multi-computer,LAM),它是由Ohio超级计算机中心开发的,适用于异构Unix机群的MPI编程环境和开发系统。目前我们所安装的LAM版本是6.5.2版。同时还安装了Fortran 90开发平台。在RedHat7.1系统安装结束以后,还安装了f2c(Fortran-to-C)软件包以及一些必要的服务软件。由于每个节点有两块网卡分别担任消息传递和接收的工作,并且两块网卡共用一个IP地址,为了实现这样的功能,必须添加一个虚拟的网络设备,将两块网卡绑定到这个虚拟的网络设备上。在外界看来,每个节点只有1个IP地址和1块网卡。在RedHat 7.1可以正常运行以后,必须启动如下的系统服务:rlogin、rsh、nfs、ftp、telnet等。其中的rlogin和rsh服务只需要在8个计算节点上配置。出于安全方面的考虑,RedHat 7.1在默认的系统设置下,是不提供rlogin和rsh服务的,用户必须手工设置必要的文件和参数,实现rlogin和rsh服务。相应的nfs(网络文件系统)必须在服务节点和计算节点上同时配置。在所有的系统服务配置成功后,就可以安装LAM6.5.2了,这个软件包是免费的,可以到 下载最新的版本,安装过程可以按照软件包自带的安装说明进行安装。安装和配置结束以后,可以在Linux提示符下运行recon -v,来测试LAM是否成功安装。
5 MPI简介
一般并行计算机系统有两个基本的体系结构:分布存储和共享存储。基于分布存储的并行计算机的每个节点都有各自的本地存储器,同时也能通过高速网络接口等方式访问其他节点的存储器。各节点通过消息传递来进行数据交换。而基于共享存储的并行机系统则是多个节点通过高速总线访问一个全局的存储器空间。这种方式由于总线带宽的限制,一般将处理器个数限制在2~16个之间。最新的并行计算机体系结构使用分布存储和共享存储混合的方式,即每个节点都是由2~16个基于共享存储的处理器组成,再由多个这样的节点通过高速的通信结构构成分布存储的并行计算机系统。MPI是由MPI论坛组织开发的适用于基于分布内存的并行计算机系统的消息传递模型。它提供了一个实际可用的、可移植的、高效的和灵活的消息传递接口标准。MPI以语言独立的形式来定义这个接口库。并提供了与C、Fortran和Java语言的绑定。这个定义不包含任何专用于某个特别的制造商、操作系统或硬件的特性。由于这个原因,MPI在并行计算界被广泛地接受。其标准已由原来的MPI-1 发展到目前的MPI-2。MPI-1标准规定了如下的规范:(1) Fortran77和C分别调用MPI子程序(函数)的命名、调用顺序以及返回值的规则,所有的MPI实现都必须遵循这些规则。从而保证遵循这些标准的MPI程序可以在任何平台上的可移植性;(2) 具体的MPI库实现由硬件供应商提供,从而开发出适合各供应商硬件的最优版本。
MPI-2规范对MPI-1进行了如下的扩展:动态进程;单边通信;非阻塞群集通信模式和通信子间群集通信模式;对可扩展的I/O的支持,叫作MPI-IO。在MPI-1中,I/O问题全部忽略。 MPI-1只定义对Fortran 77和C语言的绑定, MPI-2将语言绑定扩展到Fortran 90和C++;对实时处理的支持;扩展了MPI-1的外部接口,以便使环境工具的开发者更易于访问MPI 对象。这将有助于开发剖析(profiling) 、监视(monitoring)和调试(debugging)工具。目前已经有一些MPI实现包括了MPI-2规范中的某些部分,但还没有完全支持MPI-2规范的MPI实现。
6 MPI编程简介
(1) MPI程序构成
一个标准的MPI程序由如下部分组成:
1) 头文件 对于C程序,必须包含mpi.h头文件,而对于Fortran程序,则应包含mpif.h。
2) MPI命名约定 为了避免与语言的命名冲突,约定所有的MPI实体(包括例程、常数和类型等)都以MPI_开头。
3) MPI例程和返回值 所有MPI例程(函数或子程序)在C或Fortran调用中都返回一个整型值,用以确定MPI调用的退出状态。
4) MPI句柄 MPI定义了自己用于通信的数据结构,必须通过句柄引用这些数据结构,这些句柄由各个MPI调用返回,并可能再次用于其他的MPI调用。在C语言中,句柄是指向特定的数据类型的指针(由C中的typedef机制创建),而在Fortran语言中,句柄则是一个整型数,例如MPI_COMM_WORLD在C语言中,是一个MPI_Comm类型(一个代表所有处理器集合的通信子)的一个对象,而在Fortran中,它是一个整型数。
5) MPI数据类型 参考C和Fortran中的基本数据类型,MPI提供了自己的参考数据类型,这些MPI数据类型主要用于MPI调用中的参数。
6) MPI初始化和结束 任何MPI程序在调用MPI例程之前,都必须首先调用MPI初始化函数,从而初始化MPI环境,这个初始化例程在C程序中名为:
int MPI_Init(&argc, &argv)
而在Fortran中,则为:
MPI_INIT(INT IERR)
所有的MPI调用结束以后,必须调用MPI_FINALIZE例程,用于清理所有的MPI数据结构,取消所有没有完成的MPI操作;所有的处理器都必须调用此例程,如果任何一个处理器没有完成此调用,程序将处于挂起等待状态。在C和Fortran 中,调用的方式分别为:
C: int MPI_Finalize();
Fortran: call MPI_FINALIZE(INTEGER IERR)
7) MPI通信子(Communicators) MPI通信子是一个代表一组能够互相进行信息交换的处理器的句柄。每个通信子有各自的名称,每个通信子必须允许send和receive调用进行通信,同时只有在同一个通信子内的处理器才能够通信。
8) 获得通信子信息:(处理器)次序和(通信子)大小。处理器通过调用MPI_COMM_RANK来确定其在通信子中的次序。处理器的次序定义有如下规则:通信子中的次序是从0开始的连续整数;一个处理器在不同的通信子中可以有不同的次序。
在C程序中,函数调用形式为
int MPI_Comm_rank(MPI_Comm comm., int *rank);
其中comm是MPI_Comm类型,代表一个通信子,在Fortran中,函数形式为:
MPI_COMM_RANK(COMM,RANK,IERR)
使用MPI_COMM_SIZE可以获得任何通信子中所包含的处理器个数。
C:int MPI_Comm_size(MPI_Comm comm., int *size)
Fortran:MPI_COMM_SIZE(COMM,RANK,SIZE)
(2) MPI程序实例(以C语言为例)
#include <stdio.h>
#include <mpi.h>
void main(int argc, char *argv[]
{
int myrank, size;
//Initialize MPI
MPI_Init(&argc, &argv);
//Get my rank
MPI_Comm_rank(MPI_COMM_WORLD, &myrank);
//Get the total number of processor
MPI_Comm_size(MPI_COMM_WORLD, &size);
Printf("Processor %d of %d: Hello
World!\n",myrank,size);
//Terminate MPI
MPI_Finalize();
}
7 Beowulf 集群系统的测试
在系统安装和调试正常以后,我们对此集群系统的串行和并行计算性能与一些工作站、服务器和同类型的品牌机组成的Beowulf集群作了性能测试和比较,以下是部分具体的测试结果。
(1) 集群中单台计算机串行计算性能比较:测试所用串行程序为DVDIX[1,2]、CMA和DHOPEST,表1为部分测试数据,测试结果显示,在串行计算条件下,对所用测试程序而言,PC集群的计算速度较快。
表1 串行计算性能比较
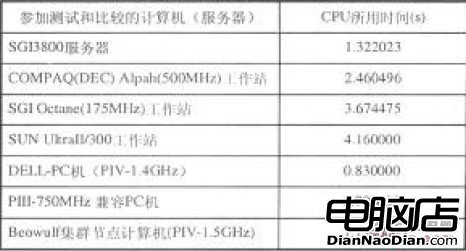
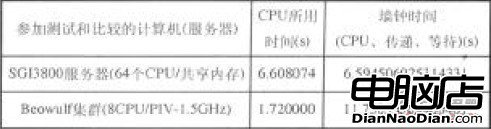
(2) Beowulf集群与其它并行计算机(集群)性能比较:
表2为Beowulf集群与SGI3800服务器的部分测试数据(均使用8个节点),根据测试结果,在程序执行时间以及墙钟时间(包括CPU、传递、等待等)等指标上,Beowulf集群与其它同类并行计算机(集群)的性能相当。
表2 并行计算性能比较
8 结语
基于Linux系统的Beowulf集群系统在等离子体物理实验以及数值模拟等方面的应用,极大地提高了运算效率和处理能力,为等离子体物理研究领域提供了一个非常有效的高性价比的工具。
