Sql Server中的表访问方式Table Scan, Index Scan, Index Seek
Sql Server中的表访问方式Table Scan, Index Scan, Index Seek
0.参考文献
oracle表访问方式
Index Seek和Index Scan的区别以及适用情况
1.oracle中的表访问方式
在oracle中有表访问方式的说法,访问表中的数据主要通过三种方式进行访问:
全表扫描(full table scan),直接访问数据页,查找满足条件的数据
通过rowid扫描(table access by rowid),如果知道数据的rowid,那么直接通过rowid进行查找
索引扫描(index scan),如果一个表创建了索引,那么可以通过索引来找出我们想要的数据在表中的存放位置,也就是rowid,通过返回rowid然后用rowid来进行访问具体数据。
而索引扫描中又可分为索引全扫描(index full scan)、索引范围扫描(index range scan)和索引唯一扫描(index unique scan)等。
2.sql server中clustered index scan,table scan,index scan
在sqlserver中也有类似的内容,这里就要将的是table scan,index scan以及index seek.
A table scan is where the table is processed row by row from beginning to end.
An index scan is where the index is processed row by row from beginning to end.
If the index is a clustered index then an index scan is really a table scan.
总结:在sql server中,对表中数据从头到尾一行一行的进行出来就是表扫描。这里的处理我们可以理解为sql中where子句的条件判断。我们需要遍历表中的每一行,判断是否满足where条件。最简单的table scan是select * from table。
索引扫描就是对索引中的每个节点从头到尾的访问。假设我们的索引是B树结构的,那么index scan就是访问B树中的每一个节点。
假如索引是聚集索引,那么B树索引的叶子节点保存的是数据页中的实际数据。假如索引是非聚集索引,那么B树叶子节点保存的是指向数据页的指针。
(ps:以下2.1-2.6于2012-9-4补充)
2.1实验数据准备
在介绍完clustered index scan,table scan和index scan以后,我们将通过实验来表述会在什么情况下使用这些表扫描方式。我们将使用AdventureWorks2008R2这个sample database进行实验,首先准备实验数据,TSQL如下所示:
View Code
--准备测试数据--------------------------------------------------
use adventureworks2008R2
go
--如果表已存在,删除
drop table dbo.SalesOrderHeader_test
go
drop table dbo.SalesOrderDetail_test
go
--创建表
select * into dbo.SalesOrderHeader_test
from Sales.SalesOrderHeader
go
select * into dbo.SalesOrderDetail_test
from Sales.SalesOrderDetail
go
--创建索引
create clustered index SalesOrderHeader_test_CL
on dbo.SalesOrderHeader_test (SalesOrderID)
go
create index SalesOrderDetail_test_NCL
on dbo.SalesOrderDetail_test (SalesOrderID)
go
--select * from dbo.SalesOrderDetail_test
--select * from dbo.SalesOrderHeader_test
declare @i int
set @i = 1
while @i<=9
begin
insert into dbo.SalesOrderHeader_test
(RevisionNumber, OrderDate, DueDate,
ShipDate,Status, OnlineOrderFlag, SalesOrderNumber,PurchaseOrderNumber,
AccountNumber, CustomerID, SalesPersonID, TerritoryID,
BillToAddressID, ShipToAddressID, ShipMethodID, CreditCardID,
CreditCardApprovalCode, CurrencyRateID, SubTotal,TaxAmt,
Freight,TotalDue, Comment,rowguid,ModifiedDate)
select RevisionNumber, OrderDate, DueDate,
ShipDate,Status, OnlineOrderFlag, SalesOrderNumber,PurchaseOrderNumber,
AccountNumber, CustomerID,SalesPersonID, TerritoryID,
BillToAddressID, ShipToAddressID, ShipMethodID, CreditCardID,
CreditCardApprovalCode, CurrencyRateID, SubTotal,TaxAmt,
Freight,TotalDue, Comment,rowguid,ModifiedDate
from dbo.SalesOrderHeader_test
where SalesOrderID = 75123
insert into dbo.SalesOrderDetail_test
(SalesOrderID, CarrierTrackingNumber, OrderQty, ProductID,
SpecialOfferID,UnitPrice,UnitPriceDiscount,LineTotal,
rowguid,ModifiedDate)
select 75123+@i, CarrierTrackingNumber, OrderQty, ProductID,
SpecialOfferID,UnitPrice,UnitPriceDiscount,LineTotal,
rowguid, getdate()
from Sales.SalesOrderDetail
set @i = @i +1
end
go
--数据准备完毕--------------------------------
2.2实验数据说明:
dbo.SalesOrderHeader_test里存放的是每一张订单的头信息,包括订单创建日期、客户编号、合同编号、销售员编号等,每个订单都有一个单独的订单号。在订单号这个字段上,有一个聚集索引。
dbo.SalesOrderDetail_test里存放的是订单的详细内容。一张订单可以销售多个产品给同一个客户,所以dbo.SalesOrderHeader_test和dbo.SalesOrderDetail_test是一对多的关系。每条详细内容包括它所属的订单编号,它自己在表格里的唯一编号(SalesOrderDetailID)、产品编号、单价,以及销售数量等。在这里,先只在SalesOrderID上建立一个非聚集索引。create index默认创建的就是非聚集索引。
按照AdventureWorks里原先的数据,dbo.SalesOrderHeader_test里有3万多条订单信息,dbo.SalesOrderDetail里有12万多条订单详细记录,基本上一条订单有3~5条详细记录。这是一个正常的分布。为了使数据分布不均匀,我们再在dbo.SalesOrderHeader_test里加入9条订单记录,它们的编号是从75124到75132。这是9张特殊的订单,每张有12万多条详细记录。也就是说,dbo.SalesOrderDetail_test里会有90%的数据属于这9张订单。主要是使用“select 75123+@i...”来搜索出Sales.SalesOrderDetail中的所有记录插入到dbo.SalesOrderDetail。一共执行9次。
2.3 table scan
sql server中表分为两种,一种是有聚集索引的聚集表,另外一种是没有聚集索引的对表。在聚集表中数据按照聚集索引有序存放,而对表则是无序存放在hash中的。以dbo.SalesOrderDetail_test为例,它的上面没有聚集索引,只有一个在SalesOrderID上的非聚集索引。所以表格的每一行记录,不会按照任何顺序,而是随意地存放在Hash里。此时我们找所有单价大于200的销售详细记录,要运行如下语句:
View Code
select SalesOrderDetailID, UnitPrice from dbo.SalesOrderDetail_test where UnitPrice > 200
由于表格在UnitPrice上没有索引,所以SQL Server不得不对这个表格从头到尾扫描一遍,把所有UnitPrice的值大于200的记录一个一个挑出来,其过程如下图所示。
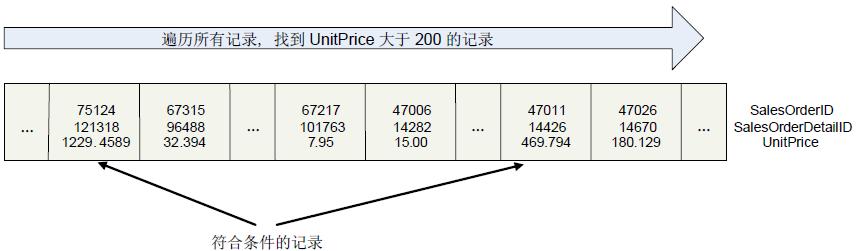
从执行计划里可以清楚地看出来SQL Server这里做了一个表扫描,如下图所示:
2.4 index scan 和 index seek
我们在SalesOrderID上创建了非聚集索引,加入查询条件是SalesOrderID,并且只SalesOrderID这一列的话,那么会以什么查询方式执行呢?首先我们查询SalesOrderID<43664的记录,执行如下TSQL语句:
select SalesOrderID from SalesOrderDetail_test where SalesOrderID< 43664
其执行计划如下图所示,我们发现执行的是index seek
假如我们要查询所有SalesOrderID记录并且不加where条件,
select SalesOrderID from SalesOrderDetail_test
那么查询计划如下图所示,我们发现执行的是index scan。
那么假如我们要求查询所有SalesOrderID<80000的记录呢,是按照什么方式查询的。在执行查询之前晴空执行计划缓存
View Code
DBCC DROPCLEANBUFFERS--清空执行计划缓存
DBCC FREEPROCCACHE--清空数据缓存
select SalesOrderID from SalesOrderDetail_test where SalesOrderID< 80000
其查询计划如下图所示,我们发现使用的是index seek
2.5 clustered index scan
如果这个表格上有聚集索引,事情会怎样呢?还是以刚才那张表做例子,先给它在值是唯一的字段SalesOrderDetailID上建立一个聚集索引。这样所有的数据都会按照聚集索引的顺序存储。
View Code
--为SalesOrderDetail_test创建聚集索引
create clustered index SalesOrderDetail_test_CL
on dbo.SalesOrderDetail_test (SalesOrderDetailID)
go
可惜的是,查询条件UnitPrice上没有索引,所以SQL Server还是要把所有记录都扫描一遍。和刚才有区别的是,执行计划里的表扫描变成了聚集索引扫描(clustered index scan)。如下图所示:
因为在有聚集索引的表格上,数据是直接存放在索引的最底层的,所以要扫描整个表格里的数据,就要把整个聚集索引扫描一遍。在这里,聚集索引扫描就相当于一个表扫描。所要用的时间和资源与表扫描没有什么差别。并不是说这里有了“Index”这个字样,就说明执行计划比表扫描的有多大进步。当然反过来讲,如果看到“Table Scan”的字样,就说明这个表格上没有聚集索引。
现在在UnitPrice上面建一个非聚集索引,看看情况会有什么变化。
View Code
--在UnitPrice上创建非聚集索引
create index SalesOrderDetail_test_NCL_Price
on dbo.SalesOrderDetail_test (UnitPrice)
go
在非聚集索引里,会为每条记录存储一份非聚集索引索引键的值和一份聚集索引索引键的值(在没有聚集索引的表格里,是RID值)。所以在这里,每条记录都会有一份UnitPrice和SalesOrderDetailID记录,按照UnitPrice的顺序存放。
再跑刚才那个查询,
select SalesOrderDetailID, UnitPrice from dbo.SalesOrderDetail_test where UnitPrice > 200
你会看到这次SQL Server不用扫描整个表了,如下图所示。这次查询将根据索引直接找到UnitPrice > 200的记录。
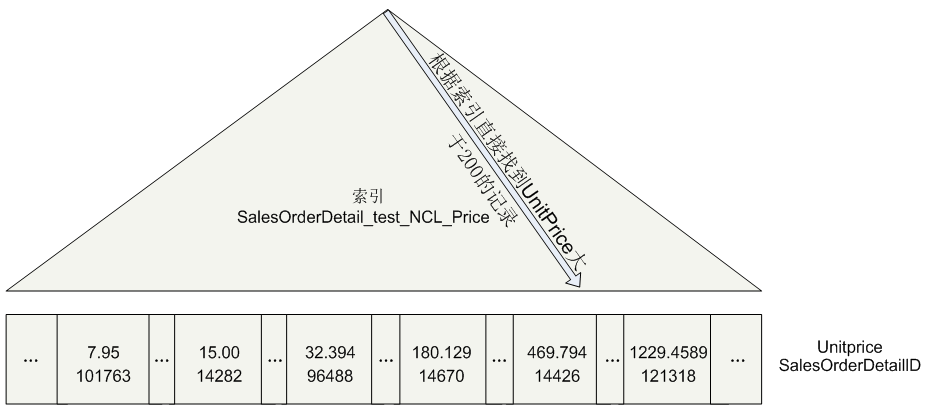
根据新建的索引,它直接找到了符合记录的值,查询计划如下图所示。我们可以看到是直接在nonclustered index上进行index seek操作。
但是光用建立在UnitPrice上的索引不能告诉我们其他字段的值。如果在刚才那个查询里再增加几个字段返回,如下TSQL查询:
View Code
select SalesOrderID, SalesOrderDetailID, UnitPrice
from dbo.SalesOrderDetail_test with (index (SalesOrderDetail_test_NCL_Price))
where UnitPrice > 200
SQL Server就要先在非聚集索引上找到所有UnitPrice大于200的记录,然后再根据SalesOrderDetailID的值找到存储在聚集索引上的详细数据。这个过程可以称为“Bookmark Lookup”,如下图所示。
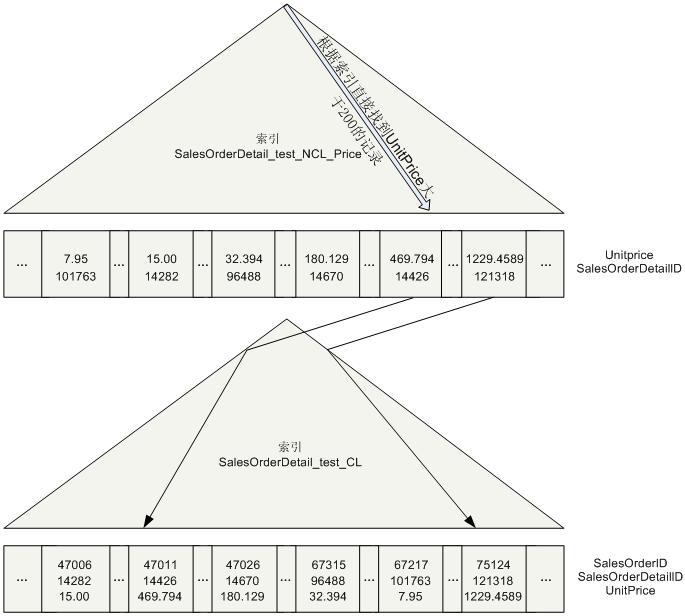
在SQL Server 2005以后,Bookmark Lookup的动作用一个嵌套循环来完成。所以在执行计划里,可以看到SQL Server先seek了非聚集索引SalesOrderDetail_test_NCL_Price,然后用Clustered Index Seek把需要的行找出来。这里的嵌套循环其实就是Bookmark Lookup,如下图所示:

上述Key Lookup就是Bookmark Lookup中的一种,这是因为我们的表中建有聚集索引,如果我们没有聚集索引,那么这里就是RID Lookup,如下图所示:

上述key lookup其所消耗的时间如下所示:
SQL Server Execution Times:
CPU time = 2995 ms, elapsed time = 10694 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
在上述查询中,之所以要使用with (index (SalesOrderDetail_test_NCL_Price))这个语句,是为了强制其使用SalesOrderDetail_test_NCL_Price这个非聚集索引,通过非聚集索引找到了聚集索引键值以后再去聚集索引中查询。如果不使用的话,sql server有可能会使用clustered index scan,也可能使用bookmark lookup,这取决于查询返回的数据量。
(1)比如还是查询UnitPrice > 200的结果:
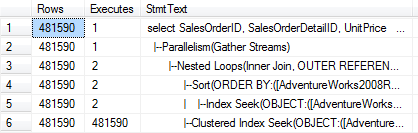
select SalesOrderID,SalesOrderDetailID,UnitPrice from dbo.SalesOrderDetail_test where UnitPrice > 200
其查询计划如下,我们可以发现使用的是clustered index scan,返回的记录数有481590条,非常大。
更重要的是其cpu time,如下所示:
SQL Server Execution Times:
CPU time = 515 ms, elapsed time = 10063 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
我们发现cpu time只有515ms,比我们之前看到的2995ms要小。这就表明:index seek 并不一定就比index scan要好。sql server会根据统计信息选择更有的方式执行操作。
(2)假如查询UnitPrice <2的结果:
select SalesOrderID,SalesOrderDetailID,UnitPrice from dbo.SalesOrderDetail_test where UnitPrice < 2
我们发现查询计划就不再使用cluster index scan了,而是使用了index seek+clustered index seek,如下图所示,返回记录数只有1630条。相对来说记录数目比较小,所以不需要clustered index scan。
2.6总结
总结一下,在SQL Server里根据数据找寻目标的不同和方法不同,有下面几种情况。
结 构ScanSeek
堆(没有聚集索引的表格数据页)Table Scan无
聚集索引Clustered Index ScanClustered Index Seek
非聚集索引Index ScanIndex Seek
如果在执行计划里看到这些动作,就应该能够知道SQL Server正在对哪种对象在做什么样的操作。table scan(表扫描)表明正在处理的表格没有聚集索引,SQL Server正在扫描整张表。clustered index scan(聚集索引扫描)表明SQL Server正在扫描一张有聚集索引的表格,但是也是整表扫描。Index Scan表明SQL Server正在扫描一个非聚集索引。由于非聚集索引上一般只会有一小部分字段,所以这里虽然也是扫描,但是代价会比整表扫描要小很多。Clustered Index Seek和Index Seek说明SQL Server正在利用索引结果检索目标数据。如果结果集只占表格总数据量的一小部分,Seek会比Scan便宜很多,索引就起到了提高性能的作用。如果查询结果集很多,那么可能会更倾向使用table scan。
3.Index Scan, Index Seek的比较
Index Seek就是SQL在查询的时候利用建立的索引进行扫描,先扫描索引节点,即遍历索引树。在查找到索引的叶子节点后,如果是聚簇索引就直接取叶子节点值的值,如果是非聚簇索引,则根据叶子节点中的rowid去查找相应的行(聚集索引的叶子节点是数据页,而非聚集索引的叶子节点是指向数据页的索引页,也就是数据页的rowid,这是在表没有聚集索引的情况下发生的;如果表本身含有聚集索引,那么非聚集索引的叶子结点中保存的是非聚集索引键值和聚集索引键值,在得到聚集索引键值以后会再去聚集索引中查找。)。而对于Index Scan是从头到位遍历整个索引页中的所有行,从头到尾,因此在数据量很大时效率并不是很高,在聚集索引的情况下,clustered index scan就是table scan。
SQL有一个查询优化分析器 Query Optimizer,其在执行查询之前首先会进行分析,当查询中有可以利用的索引时,那么就优先分析使用Index Seek进行查询的效率,假如得出使用Index Seek的查询效率并不好,那么就使用Index Scan进行查询。那究竟是在什么情况下会造成Index Seek效率比Index Scan还低呢?可以分一下集中情况:
1.在要查询的表中数据并不是很多的情况下,使用Index Seek效率不一定高,因为使用Index seek还要先从索引树开始,然后再利用叶子节点去查找相应的行。在行数比较少的情况下,还没有直接进行Index scan快。因此,表中存储的数据不能太少。
2.在返回的数据量很大的情况下,比如返回的数据量占总数据量的50%或者超过50%,使用Index Seek效率不一定好,在返回的数据量占10%-15%时,利用Index Seek能获得最佳的性能。因此假如要使用index seek,返回的数据量既不能太多,也不能太少。
3.在建立索引的列的取值很多是一致的情况下,建立索引不一定能获得很好的效率。比如不建议在“性别”列上建立索引。其实理由很简单,当建立索引的列取值的变化少的情况下,建立的索引二叉树应该是矮胖型的,树层次不高,很多行的信息都包含在叶子上,这样的查询显然是不能很好的利用到索引
MSDN原话:不要总是将索引的使用等同于良好的性能,或者将良好的性能等同于索引的高效使用。如果只要使用索引就能获得最佳性能,那查询优化器的工作就简单了。但事实上,不正确的索引选择并不能获得最佳性能。因此,查询优化器的任务是只在索引或索引组合能提高性能时才选择它,而在索引检索有碍性能时则避免使用它。
4.Sql server中的I/O
The I/O from an instance of SQL Server is divided into logical and physical I/O. A logical read occurs every time the database engine requests a page from the buffer cache. If the page is not currently in the buffer cache, a physical read is then performed to read the page into the buffer cache. If the page is currently in the cache, no physical read is generated; the buffer cache simply uses the page already in memory.
在sqlserver中I/O可以分为逻辑IO和物理IO,从缓存(buffer cache)中读取一个页(page)是逻辑读,如果数据页不在当前的缓存中,那么必须从磁盘上读取数据页到缓存中,这样算是物理读。