SQL Server数据库中存储引擎深入探讨
概述
巧妙的规划是实现关系型数据库管理系统(RDBMS)的基础。要满足对更多存储容量的要求,对更快地取得信息的要求,它是唯一方法。想从Microsoft SQL Server 7.0中获得最多,要求组织机构了解它的关键部件--存储引擎--内在和外在。本文是存储引擎结构的高级指南,推荐了配置参数,SQL Server的最佳硬件,以及通过文件和文件组存储大量数据的创新方法。本文也概述了SQL Server 7.0存储引擎的新的动态特性,它使雇员花最少的努力公司数据库应用程序。
介绍
十年前,数据库应用程序的开发要用数月或数年并不罕见。那时,当建立数据库时,每一件事情都是事先做好了的:数据库的规模,计划,用户的数目等等。现在,只要几个星期或几个月就可以开发出数据库应用程序,并随着使用不断地演进,并且在理解了所有的问题之前,应用程序就已经投入生产了。
这种任务关键的应用程序的快速应用就对存储引擎提出了严峻的要求,要求存储引擎要高度可靠,有一个快速恢复的系统和自动化管理工具。Microsoft® SQL Server™ 7.0是一个可伸缩的、可靠的并且易于使用的产品,该产品将为下一世纪应用程序的设计提供坚实的后盾。
目标
SQL Server 7.0数据引擎有几个重要的目标。明确的策略是进一步改善使用的简易性,这样使用数据库技术的应用程序就可以被广泛地应用起来。在理想的情况中,对于终端用户,数据库变为完全透明的,并且对于数据库管理者而言是近似透明的。
易用性
客户们都在寻找商业问题的解决方案。大多数数据库解决方案都带来了多重费用和复杂性问题。SQL Server 版本 6.0 和 6.5将使用的简易性定义为一个关系数据库管理系统(RDBMS)这一特征。SQL Server 7.0将这一概念带入到下一个级别当中,牢固地将产品建立为复杂性最小的数据库之一,无论是在创建,管理方面,还是在引用商业应用程序方面。
对于 SQL Server 7.0存储引擎,易用性包括许多创新的特性,包括:
· 对于标准操作无需数据库管理员。这使得分支办公室自动化,桌面和流动数据库应用程序成为可能。
· 透明的服务器配置,数据库一致性检查器(DBCC),索引统计和数据库备份。
· 最新型的和简单化了的配置选项,这些选项会自动适应环境的特殊要求。
可伸缩性
客户必须在商业应用中保护他们的投资,并且随着机构的增长,数据库也必须增长,以便处理更多的数据、事务和用户。SQL Server 7.0发表了一个独立的数据库引擎,它的范围从运行Microsoft Windows® 95或Windows 98操作系统的膝上型电脑到运行Microsoft Windows NT® Server, 企业版操作系统 的高字节容量的对称多处理器(SMP) 群集。所有这些系统都必须保持关键任务的商业系统所要求的安全性和可靠性。
以下存储引擎的特性是可伸缩性的基础:
· 新的磁盘格式和存储子系统,提供对从小型到大型数据库的存储
· 重新设计的实用工具,有效地支持TB规模的数据库
· 高内存支持,减少了频繁访问磁盘的需求
· 动态的行级锁定,允许不断增长的并行性,特别是对于联机事务处理(OLTP)应用
· 支持统一编码标准,允许使用多个国家的应用程序
可靠性
通过用简单的结构来取代复杂的数据结构和算法,SQL Server 7.0消除了许多并发性、伸缩性和可靠性方面的问题。新的结构伸缩性更好,没有并发性的问题,复杂性更低,所以也就更加可靠。
SQL Server 7.0消除了在每一个备份之前,需要运行DBCC检查的问题。关键数据结构的运行时检查使得数据库更健壮。SQL Server 7.0不再建议在每一个备份之前运行DBCC,这样DBCC明显地更快。
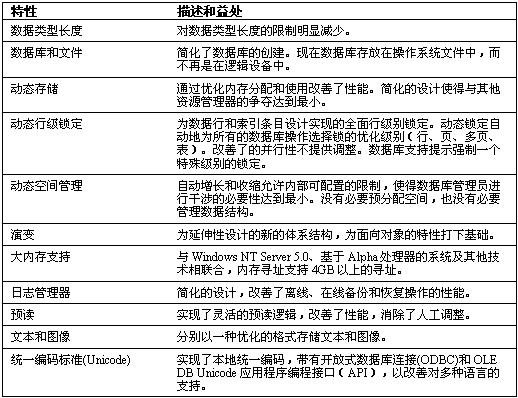
特性
下面的表格概括了SQL Server 7.0的存储引擎的特性。
存储引擎体系结构
Microsoft SQL Server 7.0的应用范围可从大型企业应用到膝上型电脑应用。这一可伸缩性是以一个新的完整系列的有关磁盘的结构为基础的,这些结构是用来处理未来几年内的应用的。
原始代码是从Sybase继承而来的,并且是设计用于8MB UNIX系统的。微软公司加强了这个代码,但是SQL Server 需要为将来打下更好的基础。新的格式改善了易管理性和可伸缩性,允许服务器的范围从低端到高端系统,以便改善性能和可管理性。
SQL Server 7.0的有关磁盘结构有许多优点,包括:
· 改善了的可伸缩性及与Windows NT Server的集成。
· 更好的性能及更大的I/O。
· 稳定的记录定位允许更多的索引。
· 更多的索引,可以加速决策支持查询。
· 更简单的数据结构,提供更好的质量。
· 更大的可伸缩性,这样后续版本将有一个更清晰的开发过程,并且可以更快实现的新特性。
存储引擎子系统
大多数关系数据库产品都被划分为关系引擎和存储引擎组件。本文档关注于存储引擎,它有许多子系统:
· 文件和查找页、文件和盘区中存储数据的机制
· 用于访问页上记录的记录管理
· 使用B树的访问方法,通过使用记录标识,该方法能够帮助迅速地查找到记录
· 锁定的并发控制,这能够帮助实现物理锁管理器和页级别或记录级别锁定的锁定协议
· I/O缓冲区管理
· 记入日志和恢复
· 用于备份、恢复、一致性检查及大批数据装载的工具
物理数据库组织
与SQL Server 以前版本相比,Microsoft SQL Server 7.0与Windows NT Server更加紧密地集成在一起。现在,数据库直接存储在Windows NT Server的文件中。UNIX遗留的数据库设备和段已经被一个简单的系统替代了,这个系统将每一个数据库映射到它自己的文件集合中。
SQL Server正在向高端和低端应用扩展。有些开发人员在中间阶段开始,并且向高端推进。他们已经引入了带有不同数据格式、语言和编程API的不同产品,以便满足高端应用程序的需要。微软满足低端需求,因为许多的Microsoft Access 客户都正在向SQL Server转移,着眼在低端应用程序所需的能力。
页和字段
SQL Server 中的基本数据存储单元是页。在SQL Server 7.0中,页的大小是8KB。在每一页的开头是一个96位的头,用于保存系统信息,如页的类型,页上空闲空间的数量以及页所属对象的ID。
在一个SQL Server 7.0数据库的数据文件中有七种页类型。

数据页包括数据行中除text、ntext和 image以外的所有数据类型,text、ntext和 image是保存在单独的页中的 。数据行是连续地放在页上,紧接在页头之后。一个行偏移的表开始于页的末尾。
行偏移表包含页上每一行的一个条目。每一个条目记录了该行的第一个字节距离页的开始的距离。行偏移表中的条目的顺序与页上行的顺序是相反的。在SQL Server 7.0中,行不能够跨越页,一行中所能够包含的最大数据量是8,060字节,这并未包括text、ntext和 imag数据类型。
盘区是基本的单元,表和索引的空间分配是以盘区为单位的。一个盘区是8个连续的页,或者是64KB。为了使自己的空间分配有较高的效率,SQL Server 7.0 不会将整个的盘区分配给数据量很小的表。
SQL Server 7.0有两种类型的盘区:统一的和混合的。统一的盘区属于一个单独的对象:盘区中的所有页都只能由属主对象使用。
SQL Server 7.0中引入的混合区域对于小型的应用程序工作得很好。在SQL Server,表的空间增加是一次一个盘区。在SQL 7中,对于微型表而言,这会导致巨大的过载,因为现在页的大小是8KB。一个混合盘区允许将一个单独页分配给一个小型表或索引。只有当分配给表或索引的页数超过了8页时,它才会开始分配统一区域。混合盘区最多由8个对象共享。一个新表或索引是从混合盘区中分配页的。当一个表或索引增长到8页时,它就转向统一盘区。
破损页检测
破损页检测保证了数据库的一致性。在SQL Server 7.0中,页的大小是8KB,而Windows NT Server 是在512字节的段中执行I/O操作的。这一差异使得写一个页的一部分成为可能,这可能在电源故障发生时,或是在第一个512字节的段正在写和8KB的I/O已经完成这两个时间之间会发生。
如果写入了第一个512字节的段,可能会出现页已经被更新,而实际上此时还没有更新。(页的时间戳在页头中,页头是页的最开始96个字节。)有几种方法来处理这一问题。你可以使用电池支持的高速缓存的I/O设备,这些设备保证要么有要么全无的I/O。如果你有这些系统之一,破损页检测就没有必要了。
通过创建一个位的掩码,SQL Server可以测试到不完整的I/O操作。在位掩码中,从页中每个段中抽取一位。每次写一个页时,该位就从它以前的状态翻转(就好象它是在磁盘上一样),并且实际状态保存在页头中。如果读了一个页且有一位处于错误的状态,这就意味着I/O操作没有完成,有一个破损页。与作校验相比,这种机制更加划算。
你可以打开或关闭破损页检测,因为当位翻转时,会在页头上做上标记。如果打开或关闭破损页检测,那么就能够观察到页中已经翻转了的状态,并且在下次读取的时候能够修改过来。
SQL Server 7.0使用一系列操作系统文件来创建一个数据库,每一个数据库都有一个独立的文件。在同一个文件中再也不可能存在多个数据库。这一简化有几个非常重要的优点:文件可以增大或收缩,并简化了空间管理。